

Como lograr realizar un top de manera eficiente en una consulta SQL Server: Optimizacion de consultas top n en grupos de filas
Optimizacion de consultas top n
En Optimizacion de consultas top n.una problema puede tener varias soluciones, en una consulta ocurre lo mismo, sin embargo no todas las soluciones son las mas optimas, cuando se trata de datos siempre debemos buscar el mejor enfoque para tener el mejor rendimiento, una solución no proporcionará el mejor rendimiento en todos los casos. Varios factores pueden influir en qué solución funciona mejor, incluida la densidad de datos, la disponibilidad de índices, etc. Para decidir sobre una solución, debe conocer sus datos, comprender cómo funciona el optimizador de SQL Server y determinar si vale la pena agregar índices importantes en términos de impacto general en el sistema.
En este artículo presentaremos un problema,posteriormente mostraremos tres enfoques para resolver el ejercio planteado y analizaremos cual solución funcionaría mejor.
Problema a resolver
El ejercicio se conoce comúnmente como Top N Per Group. La idea es devolver un número superior de filas para cada grupo de filas. Supongamos que tienen una tabla llamada Orders con atributos llamados orderid, custid, empid, shipperid, orderdate, shipdate y filller (que representan otros atributos). También tiene tablas relacionadas llamadas Customers, Employees, and Shippers. Debe escribir una consulta que devuelva las N órdenes más recientes por cliente (o empleado o remitente). «Más reciente» está determinada por la fecha de orden descendente, Escribir una solución que funcione no es difícil; el desafío es determinar la solución óptima según los factores variables y lo que es específico para su caso en su sistema. como dice el dicho, todos los caminos conducen a roma, el como se llege, y sobre todo el tiempo en que se llegue, determinara lo eficiente que podemos ser, cuando hablamos de eficienca es donde elegir el camino correcto se complica 
Además, suponiendo que puede determinar la estrategia de índice óptima para respaldar su solución, debe considerar si está autorizado y si puede permitirse crear dicho índice. A veces, una solución funcionaría mejor si el índice óptimo para soportarla estuviera disponible, pero otra solución funcionaría mejor sin dicho índice. En nuestro caso, la densidad de la columna de partición (por ejemplo, custid, si necesita devolver las filas superiores por cliente) también juega un papel importante para determinar qué solución es óptima.
Optimizacion de consultas top n
Codigo 1:Datos de muestra
Ejecute el siguiente código para crear una base de datos de muestra llamada TestTOPNSQListo y dentro de ella una función auxiliar llamada GetNums. La función auxiliar acepta un número como entrada y devuelve una secuencia de enteros en el rango 1 a través del valor de entrada.
Esta función es utilizada por el código es para rellenar las diferentes tablas con un número solicitado de filas.
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 |
SET NOCOUNT ON; IF DB_ID('TestTOPN') IS NULL CREATE DATABASE TestTOPNSQListo ; GO USE TestTOPNSQlisto; IF OBJECT_ID('dbo.GetNums', 'IF') IS NOT NULL DROP FUNCTION dbo.GetNums; GO CREATE FUNCTION dbo.GetNums(@n AS BIGINT) RETURNS TABLE AS RETURN WITH L0 AS(SELECT 1 AS c UNION ALL SELECT 1), L1 AS(SELECT 1 AS c FROM L0 AS A CROSS JOIN L0 AS B), L2 AS(SELECT 1 AS c FROM L1 AS A CROSS JOIN L1 AS B), L3 AS(SELECT 1 AS c FROM L2 AS A CROSS JOIN L2 AS B), L4 AS(SELECT 1 AS c FROM L3 AS A CROSS JOIN L3 AS B), L5 AS(SELECT 1 AS c FROM L4 AS A CROSS JOIN L4 AS B), Nums AS(SELECT ROW_NUMBER() OVER(ORDER BY (SELECT NULL)) AS n FROM L5) SELECT TOP(@n) n FROM Nums ORDER BY n; GO |
Codigo 2:Generar Datos
El código rellenará
- Clientes (Customers) con 50,000 registros
- Empleados(Employees) con 400 registros
- Remitentes (Shippers)con 10 registros
- Pedidos (Orders)1,000,000 registros
Esto generará aproximadamente 240 bytes de fila, por un total de más de 200MB . Para probar sus soluciones con otra distribución de datos, cambie los valores de las variables. Con los números existentes, el atributo custid representa una columna de particiones con baja densidad (gran cantidad de valores custid distintos, cada uno aparece un pequeño número de veces en la tabla Pedidos), mientras que el atributo shipperid representa una columna de particiones con alta densidad (pequeño número de distintos valores shipperid, cada uno de los cuales aparece una gran cantidad de veces).

|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90 91 |
DECLARE @num_orders AS INT , @num_customers AS INT , @num_employees AS INT , @num_shippers AS INT , @start_orderdate AS DATETIME, @end_orderdate AS DATETIME; SELECT @num_orders = 1000000, @num_customers = 50000, @num_employees = 400, @num_shippers = 10, @start_orderdate = '20060101', @end_orderdate = '20100531'; IF OBJECT_ID('dbo.Orders' , 'U') IS NOT NULL DROP TABLE dbo.Orders; IF OBJECT_ID('dbo.Customers', 'U') IS NOT NULL DROP TABLE dbo.Customers; IF OBJECT_ID('dbo.Employees', 'U') IS NOT NULL DROP TABLE dbo.Employees; IF OBJECT_ID('dbo.Shippers' , 'U') IS NOT NULL DROP TABLE dbo.Shippers; -- Customers CREATE TABLE dbo.Customers ( custid INT NOT NULL, custname VARCHAR(50) NOT NULL, filler CHAR(200) NOT NULL DEFAULT('a'), CONSTRAINT PK_Customers PRIMARY KEY(custid) ); INSERT INTO dbo.Customers WITH (TABLOCK) (custid, custname) SELECT n, 'Cust ' + CAST(n AS VARCHAR(10)) FROM dbo.GetNums(@num_customers); -- Employees CREATE TABLE dbo.Employees ( empid INT NOT NULL, empname VARCHAR(50) NOT NULL, filler CHAR(200) NOT NULL DEFAULT('a'), CONSTRAINT PK_Employees PRIMARY KEY(empid) ); INSERT INTO dbo.Employees WITH (TABLOCK) (empid, empname) SELECT n, 'Emp ' + CAST(n AS VARCHAR(10)) FROM dbo.GetNums(@num_employees); -- Shippers CREATE TABLE dbo.Shippers ( shipperid INT NOT NULL, shippername VARCHAR(50) NOT NULL, filler CHAR(200) NOT NULL DEFAULT('a'), CONSTRAINT PK_Shippers PRIMARY KEY(shipperid) ); INSERT INTO dbo.Shippers WITH (TABLOCK) (shipperid, shippername) SELECT n, 'Shipper ' + CAST(n AS VARCHAR(10)) FROM dbo.GetNums(@num_shippers); -- Orders CREATE TABLE dbo.Orders ( orderid INT NOT NULL, custid INT NOT NULL, empid INT NOT NULL, shipperid INT NOT NULL, orderdate DATETIME NOT NULL, shipdate DATETIME NULL, filler CHAR(200) NOT NULL DEFAULT('a'), CONSTRAINT PK_Orders PRIMARY KEY(orderid), ); WITH C AS ( SELECT n AS orderid, ABS(CHECKSUM(NEWID())) % @num_customers + 1 AS custid, ABS(CHECKSUM(NEWID())) % @num_employees + 1 AS empid, ABS(CHECKSUM(NEWID())) % @num_shippers + 1 AS shipperid, DATEADD(day, ABS(CHECKSUM(NEWID())) % (DATEDIFF(day, @start_orderdate, @end_orderdate) + 1), @start_orderdate) AS orderdate, ABS(CHECKSUM(NEWID())) % 31 AS shipdays FROM dbo.GetNums(@num_orders) ) INSERT INTO dbo.Orders WITH (TABLOCK) (orderid, custid, empid, shipperid, orderdate, shipdate) SELECT orderid, custid, empid, shipperid, orderdate, CASE WHEN DATEADD(day, shipdays, orderdate) > @end_orderdate THEN NULL ELSE DATEADD(day, shipdays, orderdate) END AS shipdate FROM C; |
Independientemente de la solución que utilice, si puede permitirse crear una indices de manera óptima, el mejor enfoque es crear un índice en la columna de partición , e incluir en la definición del índice todos los demás atributos que necesita devolver de la consulta (por ejemplo, relleno).
|
1 2 3 4 5 6 7 |
CREATE UNIQUE NONCLUSTERED INDEX idx_unc_sid_odD_oidD_Ifiller ON dbo.Orders(shipperid, orderdate DESC, orderid DESC) INCLUDE(filler); CREATE UNIQUE NONCLUSTERED INDEX idx_unc_cid_odD_oidD_Ifiller ON dbo.Orders(custid, orderdate DESC, orderid DESC) INCLUDE(filler); |
Solución ROW_NUMBER
|
1 2 3 4 5 6 7 8 9 10 |
WITH C AS ( SELECT custid, orderdate, orderid, filler, ROW_NUMBER() OVER(PARTITION BY custid ORDER BY orderdate DESC, orderid DESC) AS rownum FROM dbo.Orders ) SELECT custid, orderdate, orderid, filler FROM C WHERE rownum = 1; |

Tenga en cuenta que cuando el particionamiento está involucrado en el cálculo de clasificación, la dirección de las columnas de índice debe coincidir con la dirección de las columnas en la lista ORDER BY del cálculo para que el optimizador considere confiar en el ordenamiento de índices. Por lo tanto, si crea el índice con la lista de claves (custid, orderdate, orderid) con orderdate y orderid ascendente, terminará con una clasificación costosa en el plan. Aparentemente, el optimizador no estaba codificado para darse cuenta de que un escaneo hacia atrás del índice podría usarse en tal caso.
Solución CROSS APPLY
La solución con el operador APPLY. muestra un ejemplo para esta solución, con custid como la columna de partición y 1 como el número de órdenes más recientes para devolver por partición. Esta solución consulta la tabla que representa la entidad de particionamiento (custid) y utiliza el operador APPLY para aplicar una consulta que devuelve las órdenes más recientes (N) para cada fila externa. Esta solución es sencilla y se puede adaptar fácilmente para admitir múltiples filas por partición (simplemente ajuste la entrada a la opción TOP).
|
1 2 3 4 5 6 |
SELECT A.* FROM dbo.Customers AS C CROSS APPLY (SELECT TOP (1) custid, orderdate, orderid, filler FROM dbo.Orders AS O WHERE O.custid = C.custid ORDER BY orderdate DESC, orderid DESC) AS A; |
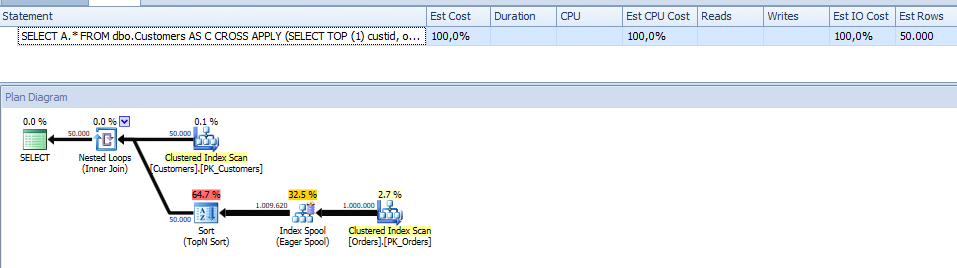
Puede ver que cuando un índice está disponible, el plan escanea la tabla que representa la entidad de partición, luego para cada fila realiza una búsqueda y escaneo parcial en el índice de la tabla Pedidos. Este plan es altamente eficiente en casos de alta densidad porque el número de operaciones de búsqueda es igual al número de particiones; con un número pequeño de particiones, hay un pequeño número de operaciones de búsqueda. Cuando ejecuté esta solución para el caso de alta densidad (con shipperid en lugar de custid), cuando el índice estaba disponible, obtuve solo 39 lecturas lógicas, en comparación con las 28,000 lecturas de la solución anterior, basadas en ROW_NUMBER. En el caso de baja densidad, habrá muchas operaciones de búsqueda, y el costo de E / S será consecuentemente alto, hasta un punto donde la solución ROW_NUMBER será más económica. Como ejemplo, cuando se usa custid como la columna de partición
Solución con concatenación
Algunas soluciones funcionan bien solo cuando los índices correctos están disponibles, pero sin esos índices las soluciones funcionan mal. Tal es el caso con ambas soluciones que presenté. Crear nuevos índices no siempre es una opción: quizás su organización tenga políticas contra hacerlo; o tal vez el rendimiento de escritura es primordial en sus sistemas, y agregar índices agrega sobrecarga a las escrituras. Si la creación de un índice óptimo para admitir las soluciones ROW_NUMBER o APPLY no es una opción, puede usar una solución basada en la agrupación y la agregación de elementos concatenados(Como dicen si no puedes con el enemigo unete a el)
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 |
WITH C AS ( SELECT custid, MAX((CONVERT(CHAR(8), orderdate, 112) + RIGHT('000000000' + CAST(orderid AS VARCHAR(10)), 10) + filler) COLLATE Latin1_General_BIN2) AS string FROM dbo.Orders GROUP BY custid ) SELECT custid, CAST(SUBSTRING(string, 1, 8) AS DATETIME ) AS orderdate, CAST(SUBSTRING(string, 9, 10) AS INT ) AS orderid, CAST(SUBSTRING(string, 19, 200) AS CHAR(200)) AS filler FROM C; |

El principal inconveniente de esta solución es que es compleja y poco intuitiva, a diferencia de las demás. La consulta de expresión de tabla común (CTE) agrupa los datos por la columna de partición. La consulta aplica el agregado MAX a la partición concatenada + orden + elementos cubiertos después de convertirlos a una forma común que conserva el orden y el comportamiento de comparación de los elementos de particionamiento + orden (cadenas de caracteres de tamaño fijo con intercalación binaria con COLLATE Latin1_General_BIN2). Por supuesto, debe asegurarse de que se conserve el comportamiento de ordenamiento y comparación, de ahí el uso del estilo 112 (AAAAMMDD) para las fechas de pedido y la adición de ceros a las ID de orden


